
운영체제: 프로세스
프로세스 (Process)
In computing, a process is the instance of a computer program that is being executed by one or many threads. It contains the program code and its activity. Depending on the operating system (OS), a process may be made up of multiple threads of execution that execute instructions concurrently.
프로세스(process)는 컴퓨터에서 연속적으로 실행되고 있는 컴퓨터 프로그램을 말한다. 종종 스케줄링의 대상이 되는 작업(task)이라는 용어와 거의 같은 의미로 쓰인다. 여러 개의 프로세서를 사용하는 것을 멀티 프로세싱이라고 하며 같은 시간에 여러 개의 프로그램을 띄우는 시분할 방식을 멀티 태스킹이라고 한다. 쉽게 말해, 프로세스는 파일로 존재하던 프로그램을 메모리에 적재해 실행중인 상태가 되었을 때 운영체제가 실행하는 프로그램을 의미한다.
그럼 프로그램과 프로세스의 차이는 무엇일까?
프로그램은 동작을 하지 않는 정적, 그리고 수동적인 개체이고, 프로세스는 메모리에 적재되어 운영체제가 실행하고 있는 동작중인 능동적 개체를 의미한다. 프로세스는 운영체제로부터 자원을 할당 받아 동작하게 되며, 여기서 자원이란, CPU, 메모리, 입출력장치, 파일 등을 의미하고 종류로는 사용자 프로세스, 시스템 프로세스로 구분된다. 예를 들어, 작업관리자를 오픈해보면 실행중인 프로세스와 메모리 할당 여부, CPU 자원 할당량 등등이 출력되고 있으며, 파일 이름으로 존재하던 개체가 여러 개일 경우, 파일 이름보다는 PID(Process ID)로 프로세스를 구분하게 된다.
프로세스 관리자
프로세스 관리자는 Window 10 기준으로 작업관리자의 프로세스 탭(tab)에서 관리되고 있으며, 프로세스 끝내기와 우선순위 결정 같은 버튼을 이용해 제어를 허락하고 있다.
터미널로는 TASKLIST 또는 TASKKILL 등의 명령어로 프로세스를 제어할 수 있다.
이런 프로세스 관리자의 역할은, 프로세스 생성 및 삭제 와 프로세스 실행(CPU 할당)을 위한 스케쥴링 결정 및 프로세스의 상태 관리 및 상태 전이 등이 있다.
여기서 말하는 프로세스의 기본적인 상태는 5가지로 분류가 되는데, 일반적으로 5-상태모델을 따르고 있다.
프로세스의 상태 모델
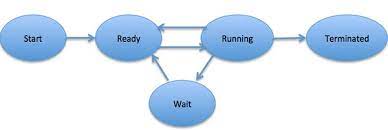
5-상태모델
생성처음 작업이 시스템에 주어진 상태준비실행 준비가 되어 CPU의 할당을 기다리는 상태대기(조건) 프로세스 특정 자원을 할당받을 때까지 또는 I/O 작업이 끝날 때까지 작업이 보류되는 상태실행프로세스가 처리되는 상태종료모든 처리가 완료되어 사용자에게 반환되는 상태
Ready 상태에서 Excute 상태로 변환하는 그 과정을 일컬어 디스패치(Dispatch)라고 불리며, 프로세스에게 CPU의 할당한 경우를 의미한다. 또한 Excute 상태에서
정해놓은 스케쥴링을 통해 정상적으로 작업을 수행했을 경우 할당시간 만료로 인해 다시 Ready 상태로 돌아가는 과정을 할당시간 만료 라고 표현한다.
미리 앞서 표현하면 작업을 수행하다가도 강제적으로 할당받은 CPU 자원을 빼앗기는 경우나 작업 수행 중 I/O 인터럽트가 발생할 경우, 그리고 그런 이벤트를 처리하고
기존의 작업을 재개하기 위한 과정 등이 있다. 이 경우는 대기 상태에서 준비상태로 돌아가는 과정이라고 할 수 있다.
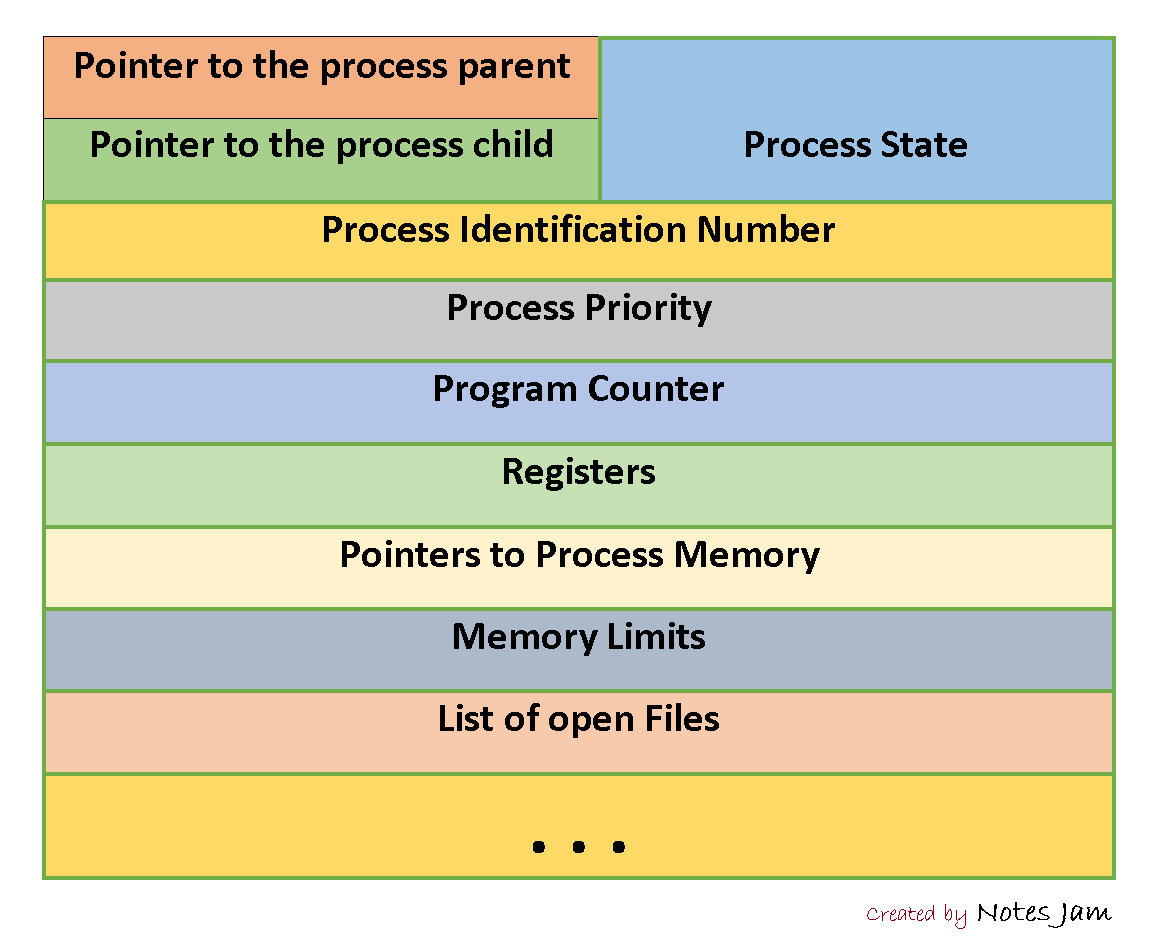
프로세스 제어 블록(PCB)
A process control block (PCB) is a data structure used by computer operating systems to store all the information about a process. It is also known as a process descriptor. When a process is created (initialized or installed), the operating system creates a corresponding process control block. Information in a process control block is updated during the transition of process states. When the process terminates, its PCB is returned to the pool from which new PCBs are drawn. Each process has a single PCB. By Wikipedia
위키피디아의 설명에서도 볼 수 있듯이, 프로세스 제어 블록은 프로세스의 모든 정보를 저장하기 위해 컴퓨터 운영체제가 사용하는 자료구조의 일종이다. Process Control Block, PCB는 프로세스 관리와 정보를 보관하고 프로세스의 상태가 바뀔때마다 상태의 정보등을 새롭게 갱신하기 위해 존재한다. 이때 PCB는 각 프로세스마다 하나씩 존재한다.
프로세스 관리자(Process Manager)가 하는 역할
1) 프로세스 생성 작업
- 프로세스의 이름(번호, PID)을 결정하고
- 준비큐(Ready Queue) 에 삽입하며
- 초기 우선순위를 부여하고 (없을수도 있다 — 메모리 도착시간이 모두 같은 경우)
- 프로세스 제어 블록(PCB) 생성 등을 제어한다.
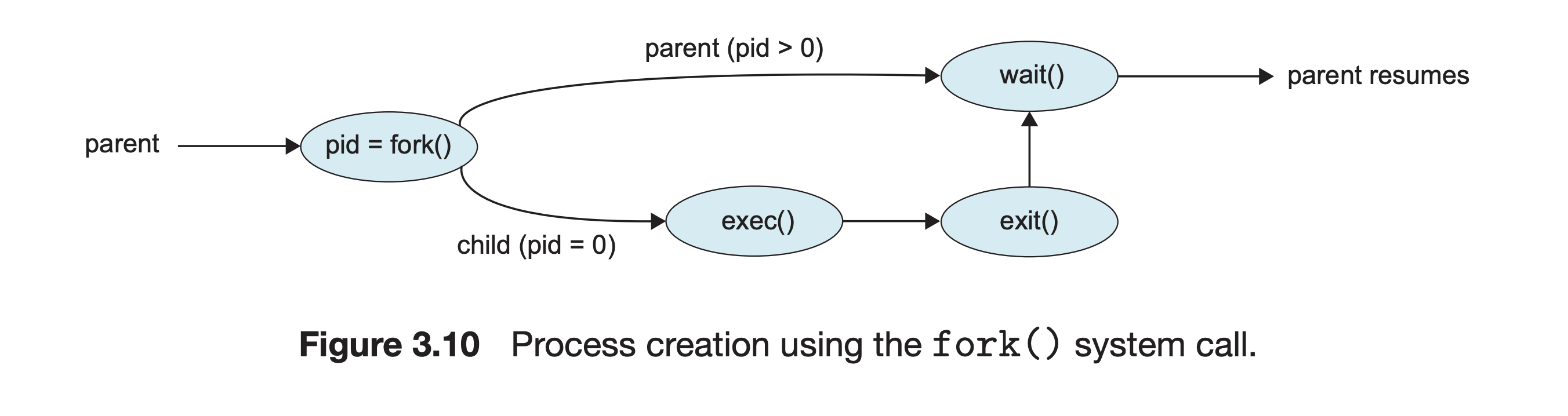
우선, 사용자 모드에서 시스템 콜(System Call)을 통하여 커널모드로 Context Switch를 수행한다. 커널 모드에서 프로세스 생성 시스템 호출인 fork() 함수를 호출해
새로운 프로세스를 생성한다.
fork():- 호출하는 프로세스 — 부모 프로세스
- 생성되는 프로세스 — 자식 프로세스 —
fork()를 통해 만들어지는 프로세스 fork()의 주체 및 대상- 시스템 프로세스와 사용자 프로세스 모두
부모 프로세스가 될 수 있다. - 부모 프로세스 또한 호출 되어질 수 있고 이는 컴퓨터 부팅 시 제일 먼저 만들어지는 최상위 프로세스(시스템 프로세스)가 호출하게 된다. 이후에 운영체제가 동작하기 위한 다양한 프로세스를 호출하게 된다.
- 생성되는 프로세스 자원
- 운영체제로부터 직접 얻는 경우
- 부모 프로세스 자원의 일부를 얻는 경우
- 시스템 프로세스와 사용자 프로세스 모두
이 때, 생성되어진 자식 프로세스는 자신을 생성한 부모 프로세스의 자원만 일부 공유받는 것으로 제한하는데 과도한 자식 프로세스 생성에 따른 시스템의 과부하를 방지하기 위해서이다.
2) 프로세스 종료 작업
- 프로세스의 마지막 명령이 실행을 마치는 경우
- 프로세스 종료 시스템 호출(exit())을 통하는 경우
- 누가 강제로 종료시키는 경우 »
누가?
- 누가 강제로 종료시키는 경우 »
- 프로세스 종류 후 부모 프로세스에게 실행결과를 되돌려줌
프로세스 종료 시스템 호출
- 부모에 의해서만 호출: 자신을 만들어냈던 부모만이 종료시스템콜을 가능하게함
- 제 3자에 의해서 종료가 되지 않게 하기 위해
- 자식 프로세스가 할당된 자원의 사용을 초과할 때 혹은 더이상 필요치 않을 때
3) 프로세스간의 관계
- 독립적 프로세스 의미: 다른 프로세스의 영향을 받지도 않고 주지도 않는다. 상태: 다른 프로세스와 상태를 공유하지 않는다. 실행의 입장: 결정적, 재생 가능(입력이 동일하면 항상 동일한 결과를 얻을 수 있다) 다른 프로세스와 무관하게 중단 및 재시작 가능 데이터의 입장: 다른 프로세스와 공유하지 않음
- 유기적 프로세스 의미: 다른 프로세스와 영향을 주고 받는다. 상태: 다른 프로세스와 상태를 공유한다(실행상태 및 자원도 포함) 실행의 입장: 비결정적, 재생 불가능(입력이 같더라도 내가 다른 프로세스와의 관계가 있기 때문에 결과물이 달라질 수 있다) 데이터의 입장: 다른 프로세스와 공유함
쓰레드
전통적인 프로세스
- 처리의 기본 단위
- 자원 소유의 단위이기도 함(하나의 주소공간)
- 디스패칭의 단위이기도 함(하나의 제어 흐름)
- 단점: 단일 프로세스안에서 동시적인 처리가 불가능하다 -> 쓰레드의 등장
쓰레드(Thread) 프로세스 내에서의 다중 처리를 위해 제안된 개념 하나의 프로세스 내에서는 하나 이상의 쓰레드가 존재 예) 프로세스A { thread A } 프로세스B { threadA, threadB, threadC } 이렇게 되면 하나의 스레드내에서는 하나의 실행점만 존재한다. (디스패칭) (함수형 프로그래밍이랑 뭔가 비슷한데)
그림으로 비교하면 편함
실행에 필요한 최소한의 정보만을 가지며, 자신이 속해있는 프로세스의 실행 환경(메모리 공간, 자원)을 공유
다중 쓰레드의 장점
- 멀티 CPU 혹은 멀티 코어 시스템 내에서는 병렬 처리가 가능하다.
- 스레드 별로 별도의 CPU, 별도의 코어를 할당시킬 수 있음(하드웨어 안에 CPU가 3개임)
- 처리 속도 쓰레드가 나누어진 경우 효율적인 처리가 가능하다. 예) 계산용 스레드, 입력용 스레드, 백업용 스레드 -> 각각의 작업을 동시적으로 할 수 있음. 이래서 자바가 병렬 처리가 가능한게 좋은걸까?, 결국 싱글 스레드는 하나의 작업만 할 수 있다는 뜻을 대충 알 것 같다. 연산이 높을 수록 프로그램의 규모가 클 수록 자바를 사용하는 이유를 알 것 같다. 파이썬은 어떻게 멀티 코어 시스템을 구현하고 있을까? 자바스크립트는 이벤트 루프를 이용한 비동기 작업 처리를 하고 있다. 이것에 단점도 한번 알아보자
스케쥴링
스케쥴링 단계: 시스템에 들어오는 작업들(1, 2, 3) 필요한 자원 요구사항 파악(1,2,3) -> 상위 단계 스케쥴링을 통해(메모리 여분 여부, 필요한 자원 여부 파악) -> 준비큐로 프로세스를 만들어 넣어준다 -> 준비큐에서 대기하고 있다가 CPU 할당을 기다린다 -> 하위 단계 스케쥴링을 통해(가용 가능한 CPU가 있는지 파악) -> CPU를 할당 -> 중간 단계 스케쥴링(현재 준비큐에 쌓여있는 프로세스들이 많아서 시스템을 여유롭게 돌리고 싶은경우) 이 스케쥴링을 통해 실행중인 작업들을 잠시 중단시켜놓고(일시중지) 쌓여있는 자원을 실행한다(신기하다) 어케짯냐 -> 시스템이 여유로워지면 다시 일시중지했던 걸 회복시켜 동작시킴 종료
상위 단계 스케쥴링
시스템에 들어오는 작업들을 선택하여 프로세스를 생성한 후 프로세스 준비 큐에 전달 선택 기준: 시스템의 자원을 효율적으로 이용할 수 있도록 하는 것 입출력(I/O) 중심 작업과 연산 중심 작업을 균형있게 선택
하위 단계 스케쥴링
사용 가능한 CPU를 준비 상태의 어느 프로세스에게 배당할지를 결정 CPU를 배당받은 프로세스는 결국 실행상태가 되어 프로세스가 처리됨 수행 주체: 디스패처(Dispatcher)
중간 단계 스케쥴링
프로세스를 일시적으로 메모리에서 제거하여 중지시키거나 다시 활성화 시킴 시스템에 대한 단기적인 부하를 조절한다
스케쥴링 아키텍처 오버뷰 그림을 이용하자
스케쥴링 정책
목표: - 공정성: 모든 프로세스가 적정 수준에서 CPU 작업을 할 수 있게 한다. - 균형: 시스템의 자원들이 충분히 활용될 수 있게 한다.
일괄 처리 운영체제의 스케쥴링 목표 - 처리량의 극대화 - 반환시간의 최소화 - CPU 활용의 극대화
대화형 운영체제 - 빠른 응답시간 - 과다 대기시간 방지
실시간 운영체제 - 처리 기한을 맞출 수 있는 스케쥴링이 필요함
운영체제별로 스케쥴링 목표가 다름
스케쥴링 정책
- 선점(Preemptive) 스케쥴링 정책
- 진행 중인 프로세스에 인터럽트를 걸고 다른 프로세스에 CPU를 할당하는 스케쥴링 전략
- 높은 우선순위의 프로세스를 긴급하게 처리하는 경우에 유용
- 대화식 시분할 시스템에서 빠른 응답시간을 유지하는데 유용
- 문맥 교환에 따른 오버헤드 발생
-
- 문맥: CPU의 모든 레지스터와 기타 운영체제에 따라 요구되는 프로세스의 상태
- CPU를 뺴앗겼기 때문에 추가적인 연산이 발생하는 것, 시간적인 손해, 하지만 실시간, 대화형에서는 선점형이 필요하다.
- 비선점(Non-preemptive) 스케쥴링 정책
- 프로세스가 CPU를 할당받아 실행이 시작되면 작업 자체가 I/O 인터럽트를 걸거나 작업을 종료할 때까지 실행상태에 있게 된다.
- 모든 프로세스가 공정하게 순서에 따라 실행된다 -> 응답시간 예측 가능
- 짧은 프로세스가 긴 프로세스를 기다리게 될 수 있음.
- 예) 하루 짜리 작업A - 1초 짜리 작업B : 하루를 기다려야함.
- OS 만드는 개발자가 원하는 스케쥴링 정책에 따라 OS를 만들 수 있음.
리눅스 러스트 스케쥴러 이따 한번보자 파이썬 스케쥴러 이따 한번보자
스케쥴링 알고리즘
배울 키워드: 스케쥴링 성능 평가 기준 스케쥴링 알고리즘
스케쥴링 성능 평가 기준
평균 대기시간이 짧을 수록, 평균 반환시간이 짧을 수록.
평균 대기시간
- 각 프로세스가 수행이 완료될 때까지 준비큐에서 기다리는 시간의 합의 평균 값
- 예) 프로세스A 대기시간 + 프로세스B 대기시간 / 프로세스의 개수 평균 반환시간
- 각 프로세스가 생성된 시점부터 수행이 완료된 시점까지의 소요시간의 평균 값
- 예) 프로세스A 반환시간 + 프로세스B 반환시간 / 프로세스의 개수
스케쥴링 알고리즘
키워드: FCFS, SJF, SRT, RR, HRN, 다단계 피드백 큐 스케쥴링(개념)
FCFS, First-Come First-Served 스케쥴링
비선점 스케쥴링 알고리즘 준비큐에 프로세스를 몰아넣고 준비 큐에 도착한 순서에 따라 디스패치(큐의 특징으로 처리함) 한번 CPU를 할당받으면 작업이 끝날때까지 반환안함.-> 비선점 방식
예) 각 A,B,C,D 프로세7의 FCFS 스케쥴링 도착시간 [0, 0, 0, 0] 프로세스 [A, B, C, D] CPU 사이클 [6, 3, 1, 4] 답) 프로세스 A,B,C,D의 대해 대기시간: [0, 6, 9, 10] 반환시간: [6, 9, 10, 14] 예) 평균 대기시간: 0+6+9+10 / 4 = 6.25 예) 평균 반환ㅅ간: 6+9+10+14 / 4 = 9.75
그림을 통해 이해하자
장점: 가장 간단한 스케쥴링 기법 단점: - 짧은 프로세스가 긴 프로세스를 기다리는 경우 - 중요한 프로세스가 나중에 수행될 수 있음 -> 비선점 방식, 레디큐이기 때문에 - 프로세스들의 도착 순서에 따라 평균 반환시간이 크게 변함 - 같은 도착 시간이지만 각각 순서가 변경할 경우 이전 프로세스의 반환시간에 따라 평균 반환시간이 차이가 나기 떄문 - CDBA에 대해 - 예) 평균 대기시간 = 8+1+0+4 / 4 = 3.25 - 예) 평균 반환시간 = 14+4+1+8 / 4 = 6.75
SJF, Shortest Job First 스케쥴링
- 비선점 스케쥴링 알고리즘
- 준비 큐에서 기다리는 프로세스 중 실행 시간이 가장 짧다고 예상된 것을 먼저 디스패치
- 뽑아내는 기준이 달라짐, FCFS방식과 비교했을 때
예) 각 A,B,C,D 프로세7의 SJF 스케쥴링 도착시간 [0, 0, 0, 0] 프로세스 [A, B, C, D] CPU 사이클 [6, 3, 1, 4] 실생시간이 가장 짧다고 생각한 것을 먼저 디스패치 [C, D, B, A]으로 정렬 가능함. -> C부터 처리
예) 각 A,B,C,D 프로세스의 SJF 스케쥴링 프로세스 [A, B, C, D] 대기시간 [8, 1, 0, 4] 평균 대기시간 = 8+1+0+4 / 4 = 3.25 반환시간 [14, 4, 1, 8] 평균 반환시간 = 14+4+1+8 / 4 = 6.75
이렇게 문제가 나오면 그림을 그리면서 나만의 스케쥴링 분석표를 만들어보자
도착시간이 0이 아니라면 도착시간 [0, 1, 2, 3] 프로세스 [A, B, C, D] CPU 사이클 [6, 3, 1, 4]
- 현재 준비큐에 A가 들어가자마자 CPU를 할당받고 비선점방식이기 때문에 인터럽트 발생 없이 작업을 끝까지 할 수 있음
프로세스 [A, B, C, D] 대기시간 [0, 6, 4, 7] 평균 대기시간 = 0+6+4+7 / 4 = 4.25 // 그래서 이 부분의 A의 대기시간이 없는 이유임 반환시간 [6, 9, 5, 11] 평균 반환시간 = 6+9+5+11 / 4 = 7.75
장점: 일괄처리 환경에서 구현하기 쉬움(어떤게 먼저 들어오고 끝날지 가늠이 가능) 단점: 실행 예정 시간 길이를 사용자의 추정치에 의존하기 때문에 실제로는 먼저 처리할 작업의 CPU 시간을 예상할 수 없음, 요새 컴퓨터의 업그레이드로 인해(멀티환경)
SRT, Shortest Remaining Time
선점 스케쥴링 알고리즘 실행이 끝날 때까지 남은 시간 추정치가 가장 짧은 프로세스를 먼저 디스패치 기존의 SJF 방식과의 차이점은 SRT 방식은 선점형인 것과 전체 실행시간이 짧은 것부터 먼저 실행하는 방식이랑은 차이점이 있다.
프로세스 A, B, C, D에 대해 도착시간 [0, 1, 2, 3] 프로세스 [A, B, C, D] CPU 사이클 [6, 3, 1, 4] 설명: A 프로세스가 들어오고 A가 CPU를 할당받고 1초 뒤에 B가 들어오면 A의 남은시간은 5이므로, 프로세스A와 프로세스B의 남은 시간을 비교해서 CPU를 재할당한다. 이 때 프로세스A는 준비큐에 다시 둔다. 갑자기 궁금증: 하나의 운영체제는 프로세스를 처리하는 하나의 스케쥴러만 가지는가? 아니면, 프로세스 유형과 종류별로 다른 스케쥴러를 가지는가?
프로세스 [A, B, C, D] 대기시간 [8, 1, 0, 2] 평균 대기시간 = 8+1+0+2 / 4 = 2.75 반환시간 [14, 4, 1, 6] 평균 반환시간 = 14+4+1+6 / 4 = 6.25 SJF 스케쥴링과 SRT 스케쥴링 평균 대기시간과 평균 반환시간을 비교해보자
장점: SJF보다 평균 대기시간이나 평균 반환시간에서 효율적 대화형 운영체제에 유용 단점: 각 프로세스의 실행시간 추적, 선점을 위한 문맥 교환(Context switch) 등, SJF보다 오버헤드가 크다. 문맥 교환이 발생하는 시점에 자원과 메모리를 PCB에 반납해야 하기 때문에 오버헤드가 큰 것임
RR, Round Robin
선점 스케쥴링 알고리즘 준비 큐에 도착한 순서에 따라 디스패치하지만 정해진 시간 할당량에 의해 실행을 제한 시간 할당량 안에 완료되지 못한 프로세스는 준비 큐의 맨 뒤에 배치, 할당 시간만큼만 CPU를 할당받아 사용하는 방식